https://www.abstractapi.com/guides/sending-email-with-python
Useful article on how to get Gmail to work with Python post May 2022 when the "Less Secure" app access was turned off.
Easiest method is to turn on 2FA and then create an application password.
=========
[ Back up of the important text from the link above ]
Two-factor Authentication
In order to allow our Python client script to access Gmail accounts we will enable two-factor authentication (2FA) which Google calls "2-step verification".
With 2FA you add an extra layer of security to your account in case your password is stolen. After you set it up, you’ll sign in to your account in two steps using:
To enable 2FA:
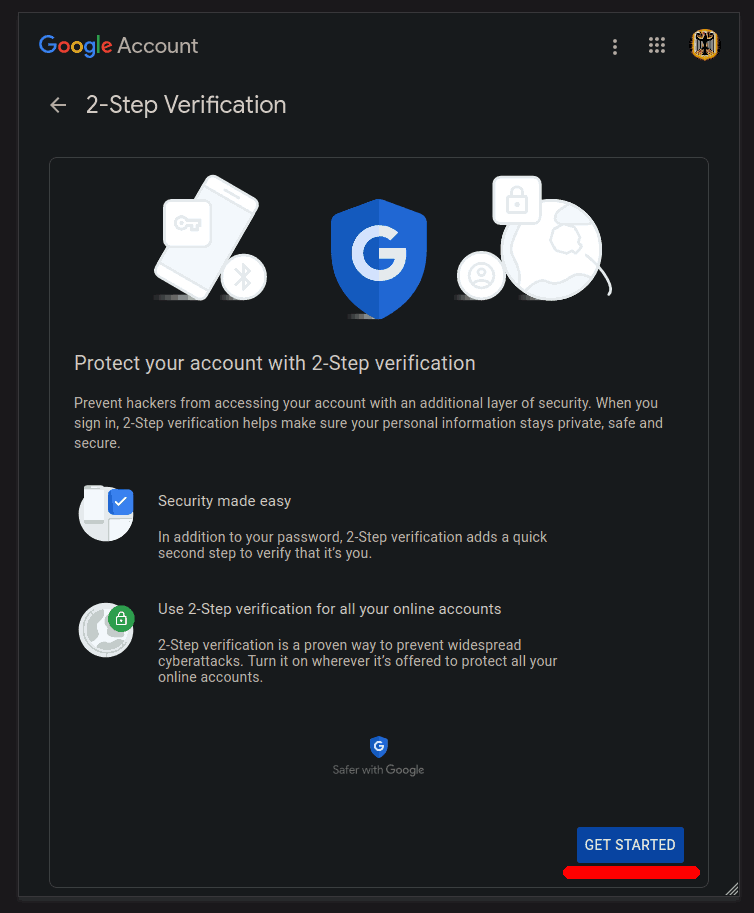
Click the blue GET STARTED button:
Login using your password. Make sure you are using the right account.
Enter your phone number and click SEND:
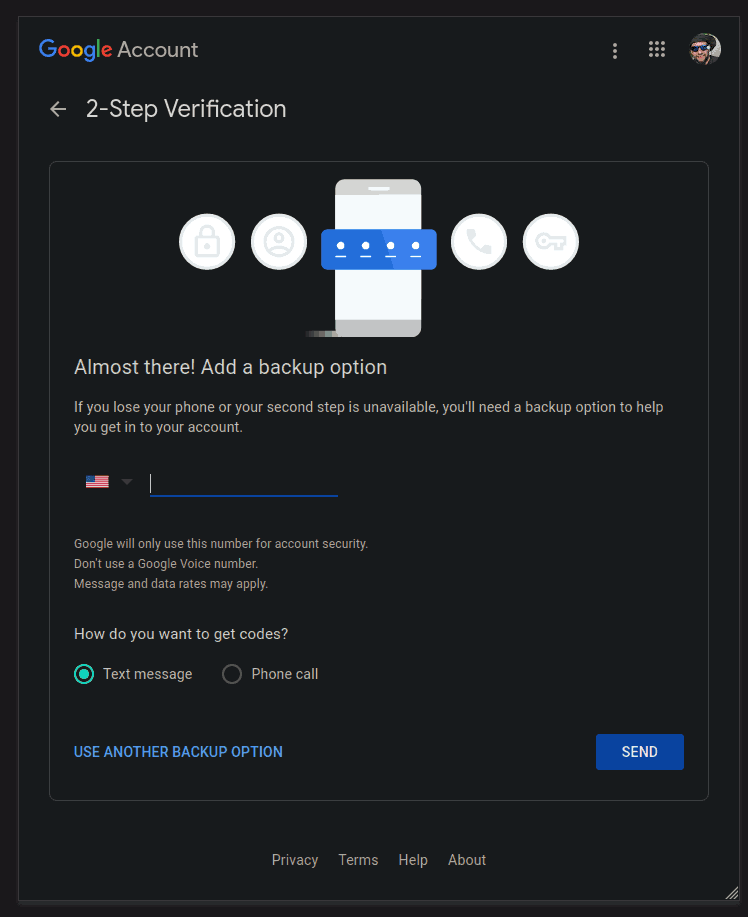
Wait for the confirmation code to arrive and enter it in:
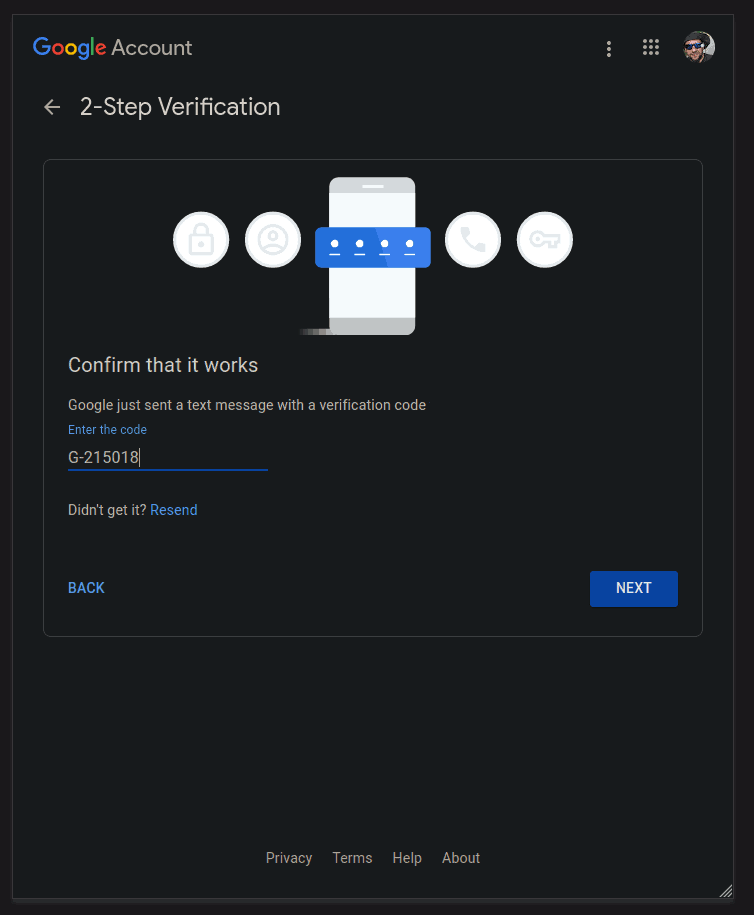
Click the TURN ON button:
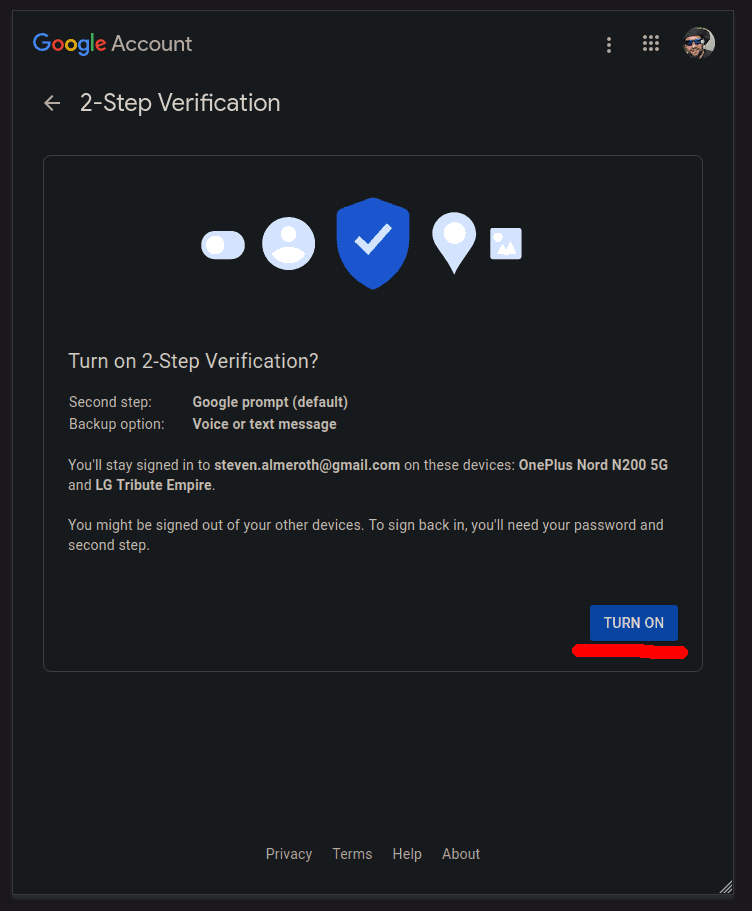
2FA should now be enabled:
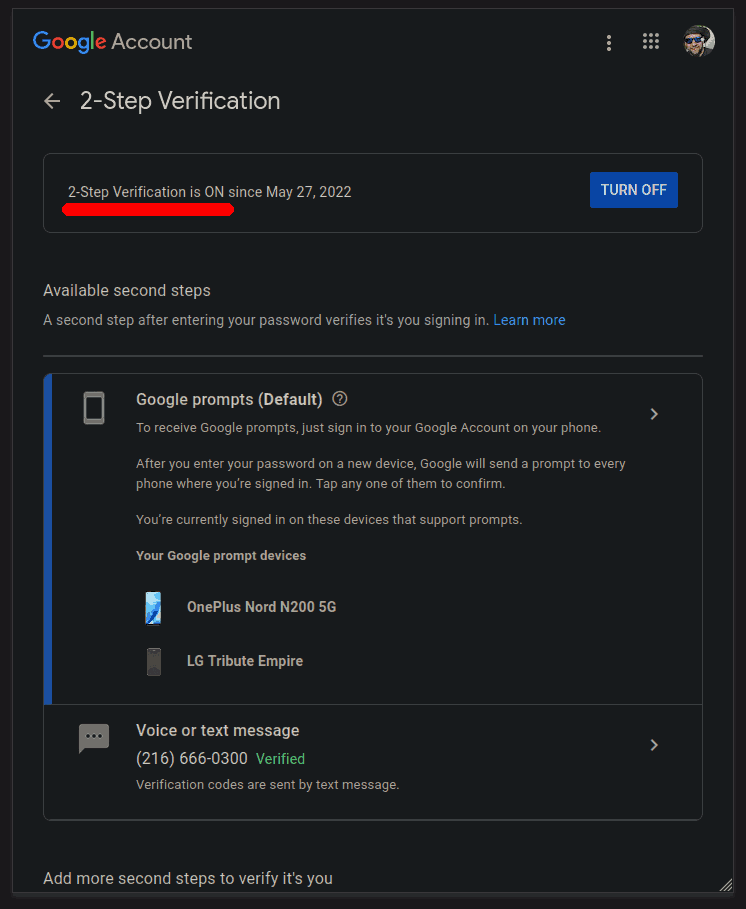
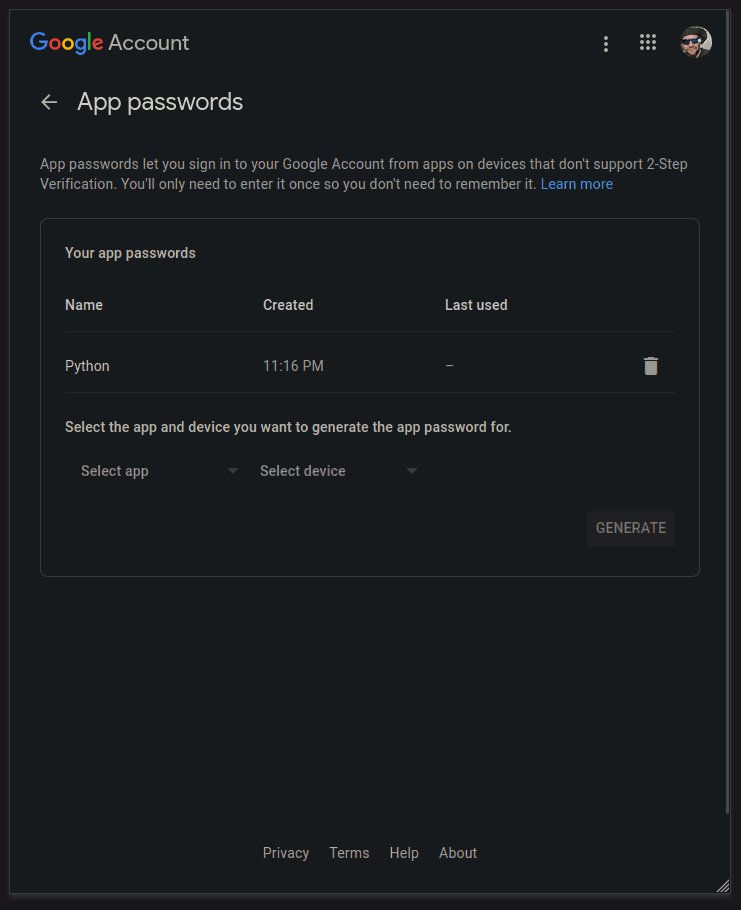
App Passwords
Now we will generate a special password that our app can use as the 2-step verification.
Back in the Signing in to Google panel select "App passwords" to add a new password:
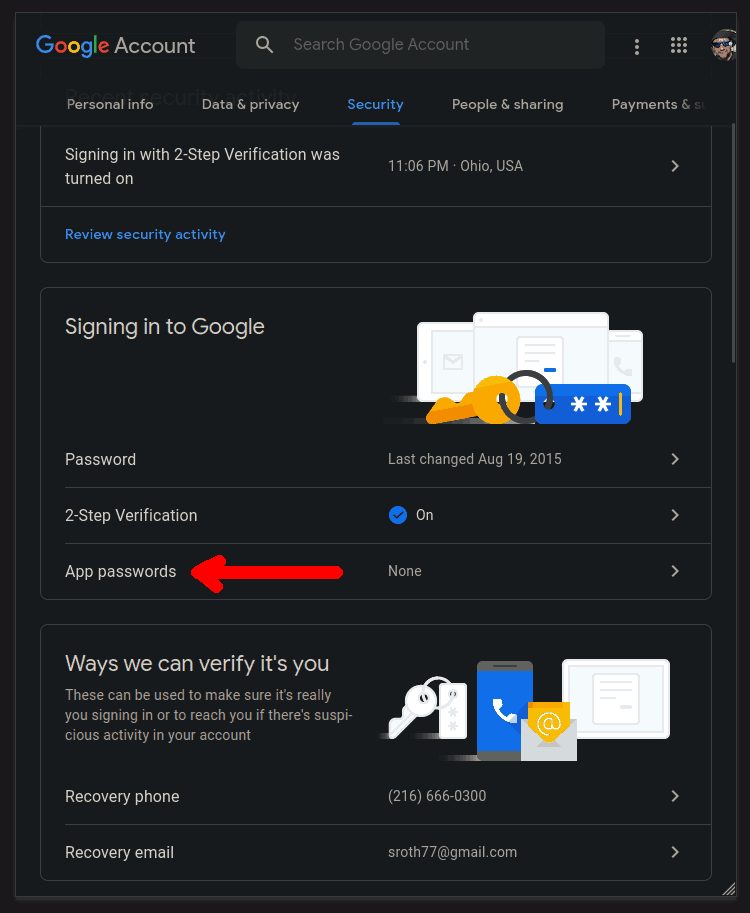
Under the "Select app" drop-down select "Other":
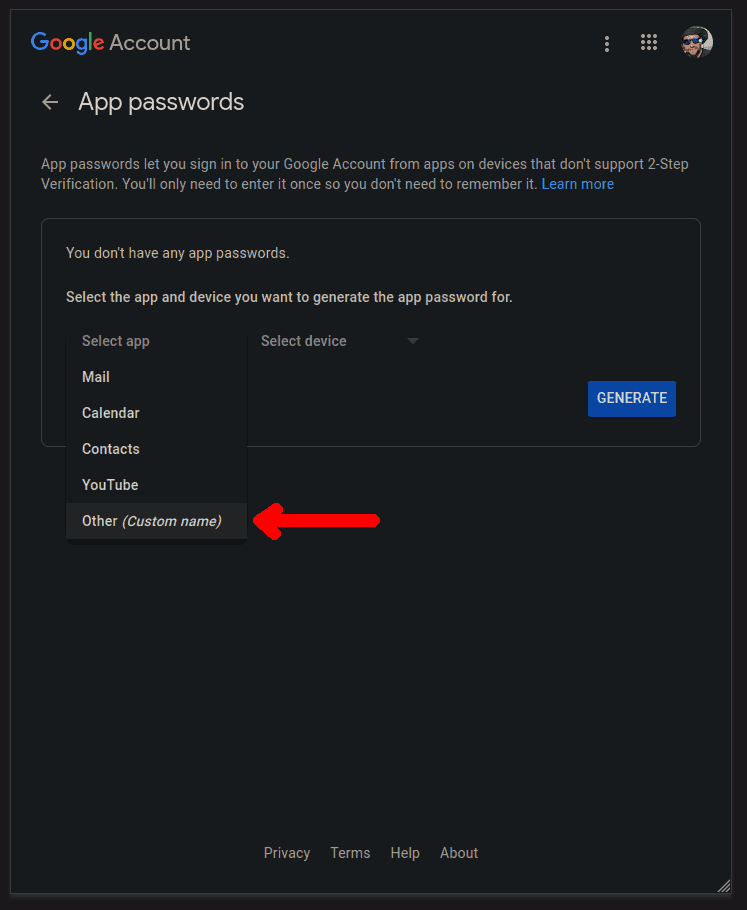
Give your app a name and click GENERATE:
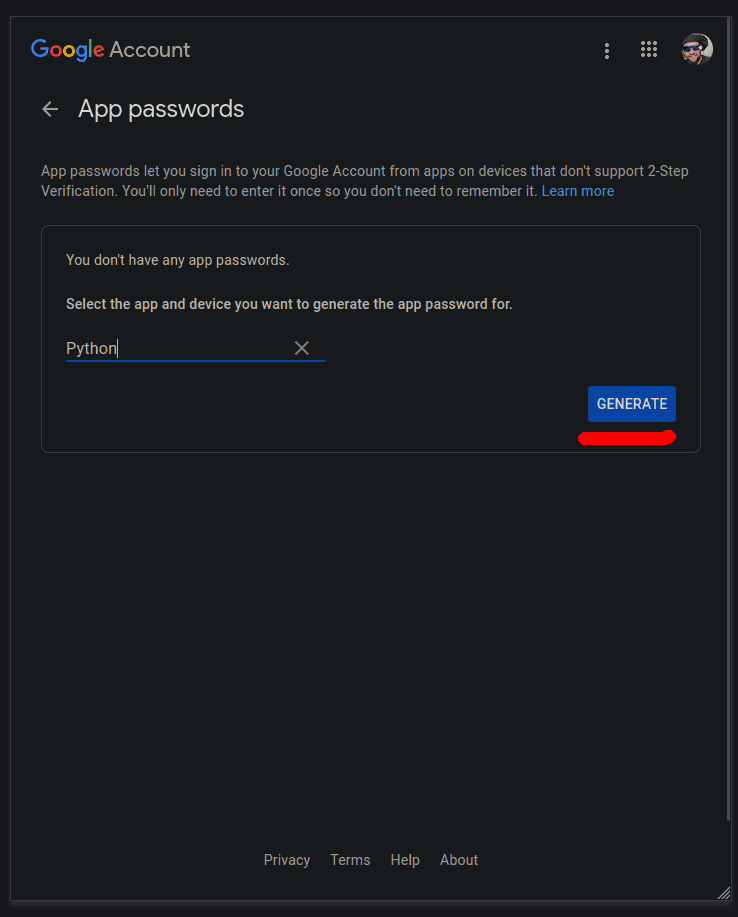
Write down (copy to clipboard) your generated password to use in the app:
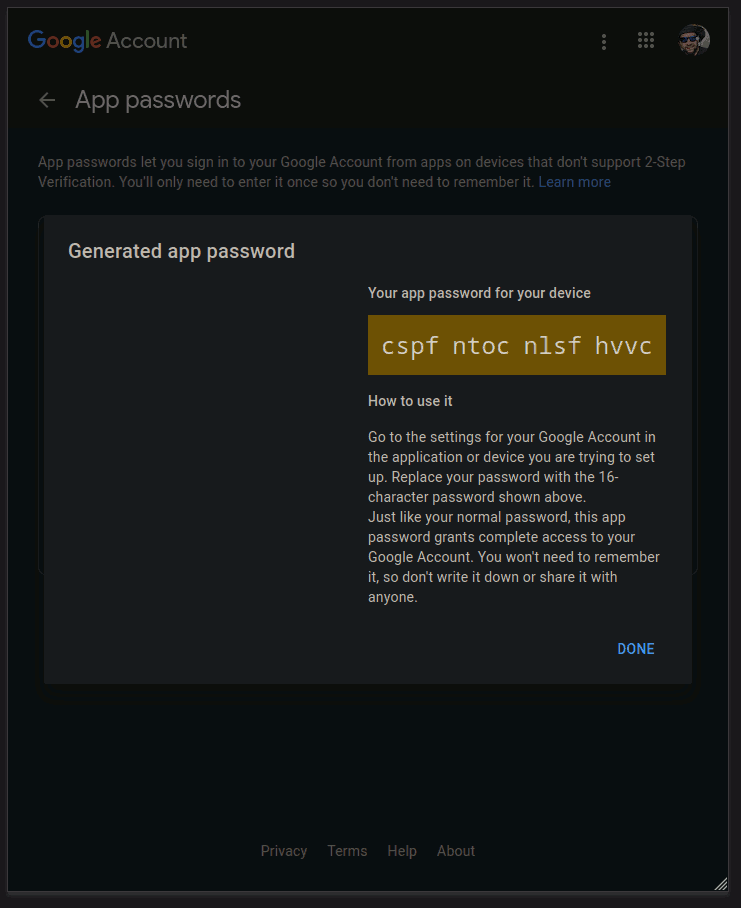
We should now have our generated app password:
Script: Plain Text
Create a file called "gmail.py" and enter the following script:
The code above creates a secure connection with Gmail’s SMTP server using Secure Sockets Layer encryption (SSL) and automatically upgrades it to TLS. Passing in the context from the create_default_context() function will load the system’s trusted CA certificates, enable certificate validation and hostname checking and try to choose reasonably secure protocol and cipher settings.
Notice how the message variable actually contains a newline as the first character.
Note: Be sure to fill in your: password, sender and receiver strings.
Save the file and go to your terminal and run the script:

{kind=link}